
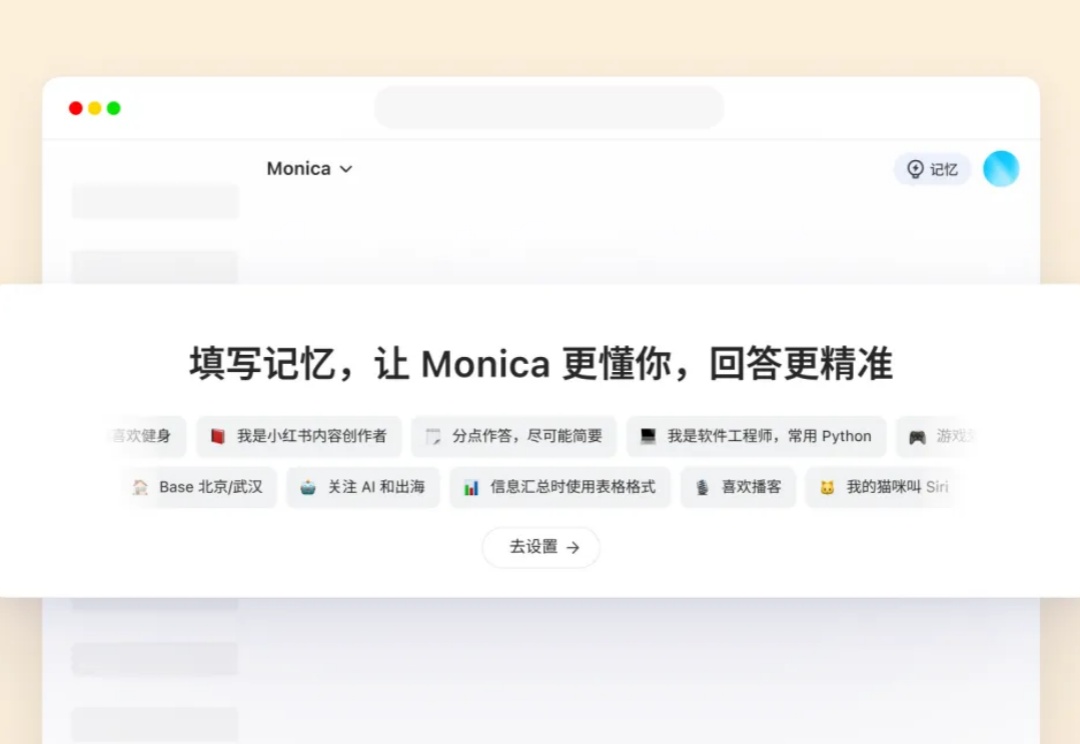
Monica上线国内版,基于满血版R1,FP读者专享内测码限量领取
Monica上线国内版,基于满血版R1,FP读者专享内测码限量领取知名 Chatbot 及各种 AI 工具箱产品 Monica 最近推出了国内版Monica.cn,基于 DeepSeek R1 与 V3模型,并且具备实时联网搜索与记忆能力。
来自主题: AI资讯
9415 点击 2025-02-25 10:26
知名 Chatbot 及各种 AI 工具箱产品 Monica 最近推出了国内版Monica.cn,基于 DeepSeek R1 与 V3模型,并且具备实时联网搜索与记忆能力。

就在刚刚,Anthropic祭出首个混合推理Claude 3.7 Sonnet,堪称扩展思考模式的最强模型。在最新编码测试中,新模型暴击o3-mini、DeepSeek R1,AI编码王者出世了。
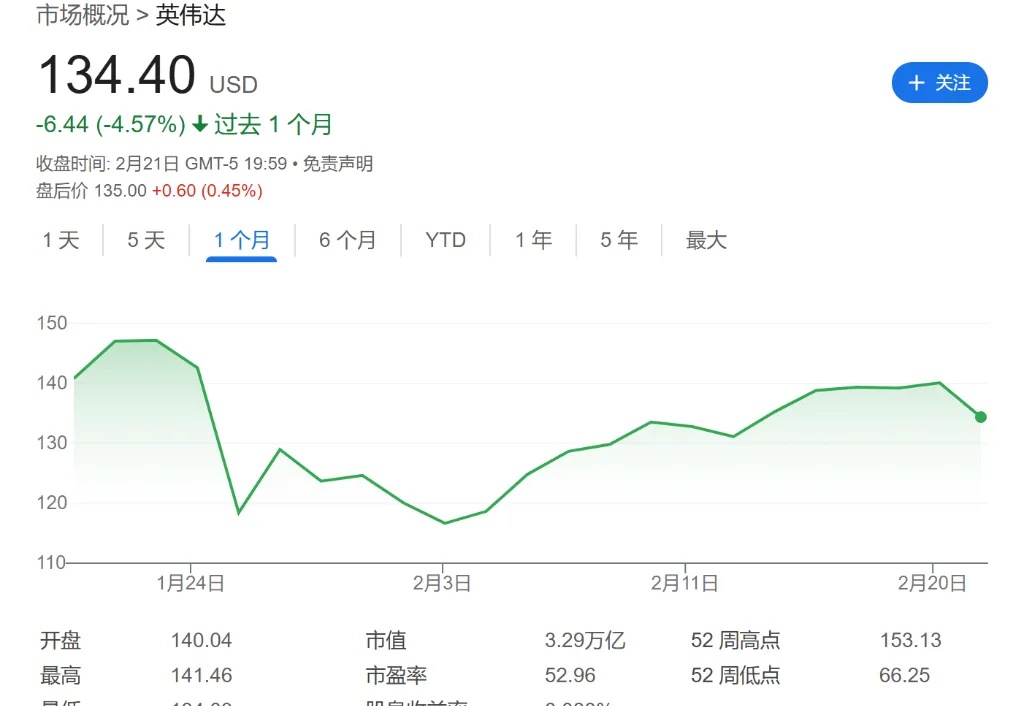
DeepSeek的横空出世引发大模型算力逻辑的质疑,英伟达股价一度暴跌。然而,黄仁勋却在最新访谈中表示,市场对DeepSeek的理解“完全搞反了”。
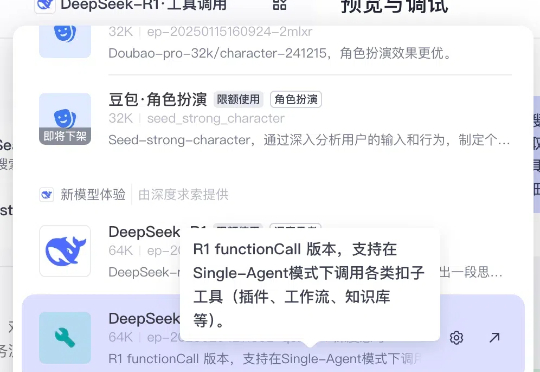
众所周知,目前 DeepSeek R1 有一个很大的痛点是不支持 Function Call 的。GitHub 上有许多开发者都表达了这一诉求。

嘿,各位开发小伙伴,今天要给大家安利一个全新的开源项目 ——VLM-R1!它将 DeepSeek 的 R1 方法从纯文本领域成功迁移到了视觉语言领域,这意味着打开了对于多模态领域的想象空间!

大模型混战,一边卷能力,一边卷“低价”。 DeepSeek彻底让全球都坐不住了。 昨天,马斯克携“地球上最聪明的AI”——Gork 3在直播中亮相,自称其“推理能力超越目前所有已知模型”,在推理-测试时间得分上,也好于DeepSeek R1、OpenAI o1。不久前,国民级应用微信宣布接入DeepSeek R1,正在灰度测试中,这一王炸组合被外界认为AI搜索领域要变天。

当 DeepSeek 在春节期间爆火,所有人都在猜测国内 AI 厂商将会如何跟进时,腾讯元宝上周宣布接入满血版 DeepSeek R1,APPSO 体验后彻底告别了「服务器繁忙」。而就在刚刚,腾讯元宝正式推出自研的 Hunyuan T1 快速深度思考模型,给了我们两种深度思考模型的选择,APPSO 也提前体验了这款模型,第一时间给大家送上使用指南。

“张小龙觉得对这个功能自己最满意的地方之一,就是一经发布几乎没有改进余地而稳定运行了十年。”极客公园创始人张鹏在与张小龙对话后,这样总结微信的产品逻辑。这一点在微信成为真正意义上的“国民社交App”之后,也没有发生改变。

一觉醒来,AI应用的天变了!而且据腾讯回应消息,接入的还是满血版 DeepSeek R1!微信正在灰度测试该模型,部分灰度到的用户可以内测相关的 AI 搜索功能。

英伟达巧妙地将DeepSeek-R1与推理时扩展相结合,构建了全新工作流程,自动优化生成GPU内核,取得了令人瞩目的成果。